以太坊黄皮书(三)
区块、状态以及交易
全局状态
全局状态(状态)是一个地址集(160位标识符)与账号状态集(序列化为RLP的数据结构)之间的映射。虽然这个映射并不存储在区块链上,我们仍然假设其具体实现会在一个修改过的默克尔树(trie,字典树)中维护这个映射关系。字典树需要一个简单的后台数据库维护字节数组到字节数组之间的映射关系,这个数据库称为状态数据库。这样做有很多好处:
- 这个数据结构的根节点是加密依赖其全部的内部数据,因此它的散列值可以作为整个系统的安全标识符使用
- 作为一个不可变的数据结构,它允许通过简单的切换根散列值来回溯到任意一个前续状态(根散列是已知晓的)
因为在区块链中存储了所有的根散列值,所以能够很简单的回退到旧的状态。
账号状态包括下列4个字段:
- nonce:标量,等于从当前地址发出的交易数量。对于带有关联代码的账户,等于当前账号创建的合约数量。对处于状态的账号a,该值用表示
- balance:标量,与当前账户持有Wei的数量相同,用表示
- storageRoot:一棵对账户的存储内容(256比特整数值之间的一个映射)进行编码的默克尔树的根节点的256比特散列值。字典树的内容是一个256比特整数的Keccak 256比特散列与RLP编码的256比特值之间映射关系的编码。这个散列值用表示
- codeHash:当前账号的EVM代码的散列值,这个代码只有接收到一个消息调用时才执行;该字段是不可变的,因此和其他字段不同的是在创建以后无法修改。所有的这些代码段都包含与他们的散列值对应的状态数据库中,以用于后续检索。该散列值用b表示,且已知
为了引用存储在字典树底层的键值对集合而非引用字典树的根散列值,定义了下面的等式: 其中,$L^*_I$是字典树中键/值对的塌陷函数(collapse function)是以基础函数$L_I$在元素级的变体定义的,其中$L_I$定义如下:
并不是账号的“物理”成员,也不会为其随后的序列化贡献任何力量。
如果codeHash字段是空字符串的Keccak-256散列,例如,, 那么这个节点就表示一个简单账号,有时也称作“非合约”账号。因此我们可以定义一个全局状态塌陷函数: 其中, 函数和字典函数一起为全局状态提供一个短标识符(散列),假设: 其中是账号的验证函数:
交易
一笔交易是对以太坊来说一个外部操作者发起的一条简单的加密签名指令。外部操作者是一个自然人,软件工具可以用于其创建和传播。目前存在2种交易:
- 产生消息调用的交易
- 产生带有关联代码的新账户的创建(以非正式名称“合约创建”而熟知)的交易
这2种交易都指定了一些通用字段:
- nonce:标量,与发送者发送的交易数相同,用表示。
- gasPrice: 标量,等于执行当前交易所消耗的计算量以每单位gas需要支付的Wei数,用表示。
- gasLimit:标量,等于执行当前交易所要使用的gas上限。这个值是在任何计算完成之前预支的,随后可能并不增加,用表示。
- to:消息调用接收者的160比特地址,对于合约创建交易,此处用表示仅有的$\mathbb{B_0}$的成员,用表示。
- value:标量,与准备转给消息调用的接收者的Wei数一致,对于合约创建来说作为新创建的账号的资金,用表示。
- v, r, s:与交易的签名有关的值,被用于判定交易的发送者,用表示。
此外,一笔合约创建交易包括:
- init:一个没有大小限制的字节数组,设定账户初始化过程的EVM-code, 用表示。
init是一个EVM-code片段,其返回的是在每次收到消息调用(通过交易或者内部代码执行)时需要执行的第二个代码段 — body。init只在账号创建时执行一次,随后立即被丢弃。
相反,一个消息调用交易包括:
- data:一个没有大小限制的字节数组,用于指定消息调用的输入数据,用表示。
这里假设除了任意长度的字节数组和,所有的模块都用RLP解释为整数。 其中,(15)
地址散列有稍许不同:要么是以个20字节的地址散列或者,要么对于合约创建交易(因此形式上等价于)来说它是RLP空字节序列,因此也是的成员:
区块
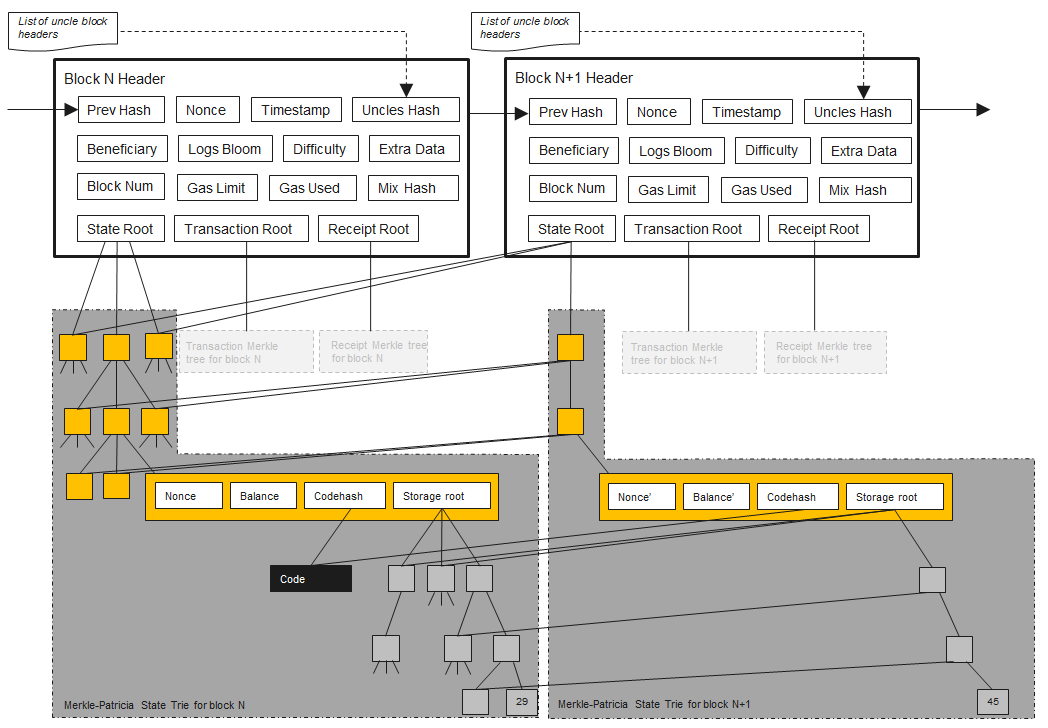
在以太坊中区块是由相关信息的头部H, 包含的交易信息T,以及其他与当前区块的父节点具有相同父节点的区块头(即叔节点的区块头)集合U组成。
区块头部包含下列信息:
- parentHash:父区块头完整的Keccak 256位散列,用表示
- ommersHash:叔区块列表的Keccak 256位散列,用表示。
- beneficiary:为成功采集到当前区块所手机的有费用的160位转移地址。
- stateRoot:在全部交易执行完成之后,状态字典树根节点的Keccak 256位散列,用表示。
- transactionsRoot:字典树结构的根节点,携带当前区块交易列表中每一笔交易的Keccak 256位散列,用表示。
- receiptsRoot:字典树结构的根节点,携带当前区块交易列表中每一笔交易收据的Keccak 256位散列,用表示。
- logsBloom:由交易列表中的每一笔交易收据中所包含的日志条目的可索引信息(日志地址和日志主题)组成的布隆过滤器,用表示。
- difficulty:与当前区块的难度级别相关的标量。可以通过前驱区块的难度级别与时间戳计算得出,用表示。
- number:当前区块的所有前驱区块的数量,创世区块的number为0,用表示。
- gasLimit:标量,与目前每个区块的gas配额限制相同,用表示。
- gasUsed:标量,与当前块中所有交易所耗费的gas总数相同,用表示。
- timestamp:标量,与当前块诞生时的Unix系统time()合法输出相同,用表示。
- extraData:一个包含当前区块相关数据的字节数组,必须小于等于32字节,用表示。
- mixHash:一个256位的散列值,与nonce一起用于证明在当前区块上已经执行了足够的计算,用表示。
- nonce:一个64位散列值,与mixHash一起用于证明在当前区块上已经执行了足够的计算,用表示。
区块的另外两个模块比较简单,只是叔区块的头部列表(格式与前面描述的头部格式相同)和当前块中包含的交易序列。形式上说我们可以定义区块B为:
交易收据
为了将一笔交易中对构成一个零知识证明有用的信息进行编码,或者进行索引与搜索,我们编码了每一笔交易的收据,其中包含交易执行的信息。对于第笔交易,其收据用表示,并放置于一个键索引的字典树中,树的根节点在区块头部中以记录。
交易收据是一个带有4个成员的元组,其成员包括:
- 交易后状态,
- 截止当前交易发生时刻,包含当前交易的区块中累积使用的gas量,
- 当前交易执行过程中创建的日志集合,
- 从日志信息中选择的布隆过滤器
即,一个交易收据可以表示为: 函数用于为正在转换成一个RLP序列化的字节数组准备一个交易收据: 因此,交易后状态会被编码进一个字典树结构,其根节点为第一个成员。
需要声明累积使用的gas量是一个正整数,并且日志布隆过滤器是一个2048比特(256字节)的散列: 日志集合是一些列日志条目,例如。一个日志条目是一个由日志记录器地址, 一系列32字节的日志主题和数个字节的数据构成的元组: 布隆过滤器函数$M$用于将一个日志条目缩减成一个256字节的散列值: 其中,是一个特殊的布隆过滤器,它对给定的任意一个字节序列从2048个比特中设置3个比特。其实现是通过对字节序列的Keccak-256散列的前3对字节的最低11比特进行操作: 其中,是比特引用函数,例如等于字节数组中下标为的比特(下标从0开始)。
整体有效性
当且仅当区块满足下列条件时开可以说它是有效的:其必须和叔区块以及交易区块散列保持内部一致性,并且给定的交易集在基础状态(继承自父区块的完成状态)的基础上按顺序执行,从而生成一个新实体的状态: 其中是一对简单的RLP变换,这里第一个元素是交易在区块中的下标,第二个元素是交易收据: 进一步说: 因此即包含状态与RLP编码的值的键值对的默克尔树的根节点的散列,是区块的父区块。
源于交易计算的结果集,确切的说是交易收据以及交易状态累积函数在下文列出。
序列化
函数和是区块及其区块头部的准备函数。与交易收据准备函数类似,当需要RLP变换的时候,需要判断类型和结构顺序: 和都是元素级别的序列转换函数,因此: 分量类型定义如下: 其中,。关于如何构建一个正式的区块结构现在有了严格的规范,RLP
函数则提供了权威的方法将区块结构变换成一个可用于传输的字节序列。
区块头部校验
定义为区块的父亲区块,形式如下: 区块号通过父区块号递增1获得: 一个区块的头部$H$的难度定义为$D(H)$: 其中:
区块头部的gas限制必须满足关系:
是区块的时间戳,且需满足关系:
这个机制迫使区块之间以时间来保持内部平衡,最新两个区块之间一个更小的时间窗会导致难度级别的增加,从而需要额外的计算来延长下一个时间窗。相反,如果时间窗太大则难度,即下一个区块的期望时间会被缩小:
是新区块的头部,但是没有nonce和mix-hash分量,d是当前的DAG — 一个计算mix-hash需要的庞大的数据集,PoW是工作量函数:这个计算得出一个数组,第一个元素是mix-hash用于证明使用了一个正确的DAG;第二个元素是一个密码学上依赖于H和d的随机数。对于区间[0, )上近似于均态的分布,找到结果的期望时间与难度成正比。这是区块链的安全基础,也是为什么恶意节点无法将新创建的可以重写历史记录的区块进行传播的根本原因。由于nonce需要满足这个需求,且因为其满足的情况依赖于区块的内容,从而反过来随着时间推移,区块中包含的交易用于创建新的有效区块会非常困难,几乎需要矿工中全部可信节点的计算力才能完成。
因此我们可以定义头部校验函数: 其中,,extraData最大不超过32字节。