How Does MySQL Implement JSON
MySQL JSON representation
As for MySQL 5.7.8 JSON document is supported natively by MySQL server. How does MySQL provide native support of JSON? In fact JSON document support is implemented with two phases:
- Processing phase
- Store phase
While processing JSON document MySQL provides series of functions to manipulate JSON documents in MySQL server. The JSON document in processing is loaded into memory as JSON DOM objects, and that's why JSON document could be processed fast.
How does MySQL store processed JSON document? In order to provide high performance with convinence for JSON document, MySQL stores JSON document as binary string with type identifier information, and below will discuss the details.
Serialization
JSON document in MySQL is serialized into binary string in disk and deserialized into JSON DOM object in memory. The binary format is shown as below diagram:
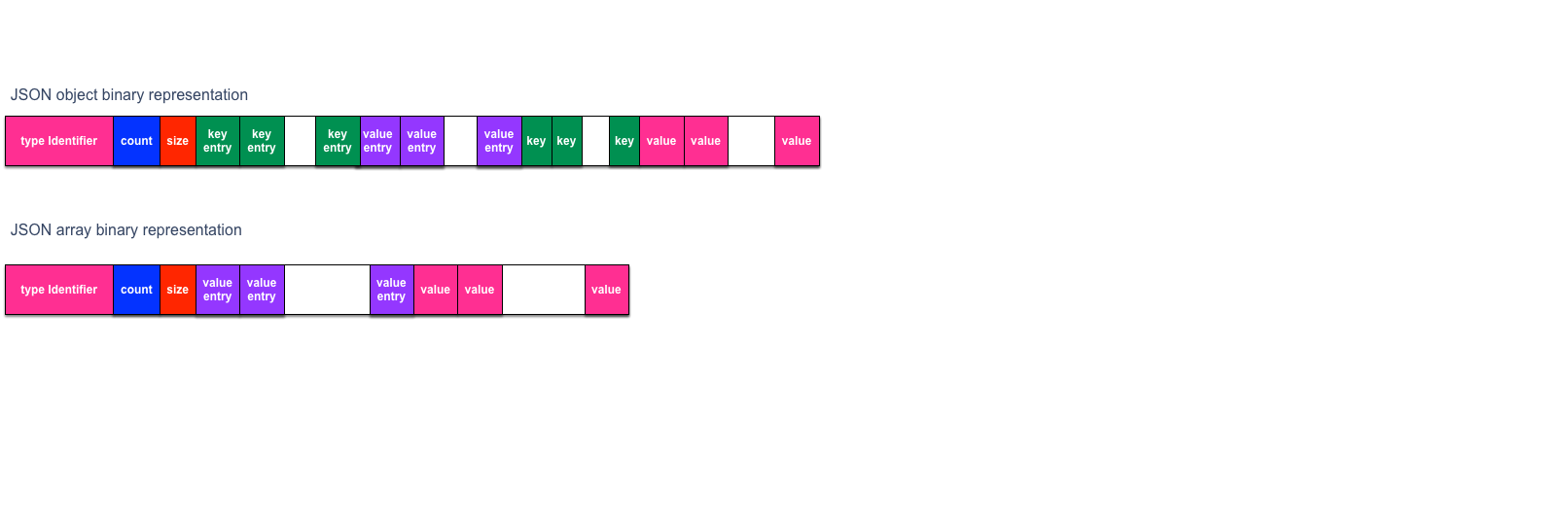
That's to say one JSON document is stored as a binary string that composed with JSON type identifier and JSON document values: JSON = type + value. Type identifier is used to identify which type of the JSON document is stored. As per the Spec of JSON there are two forms of complicated JSON value, object and array:


The value could be string, literal(true/false/null), number, object or array and they could be nested. MySQL supports all the forms of JSON document with document size concern. If one document is larger than 64KB it will be treated as a large JSON document, otherwise will be treated as a small one.
Type Identifier
As previous description, the type identifier is used to mark what is type of stored JSON document. The length of type identifier is 1 byte, with following values:
- 0x00 small json object
- 0x01 large json object
- 0x02 small json array
- 0x03 large json array
- 0x04 literal (true/false/null)
- 0x05 int16
- 0x06 uint16
- 0x07 int32
- 0x08 uint32
- 0x09 int64
- 0x0a uint64
- 0x0b double
- 0x0c utf8mb4 string
- 0x0f custom data (any MySQL data type)
These values are defined as macros in /mysql-server/sql/json_binary.cc:
#define JSONB_TYPE_SMALL_OBJECT 0x0
#define JSONB_TYPE_LARGE_OBJECT 0x1
#define JSONB_TYPE_SMALL_ARRAY 0x2
#define JSONB_TYPE_LARGE_ARRAY 0x3
#define JSONB_TYPE_LITERAL 0x4
#define JSONB_TYPE_INT16 0x5
#define JSONB_TYPE_UINT16 0x6
#define JSONB_TYPE_INT32 0x7
#define JSONB_TYPE_UINT32 0x8
#define JSONB_TYPE_INT64 0x9
#define JSONB_TYPE_UINT64 0xA
#define JSONB_TYPE_DOUBLE 0xB
#define JSONB_TYPE_STRING 0xC
#define JSONB_TYPE_OPAQUE 0xF
#define JSONB_NULL_LITERAL '\x00'
#define JSONB_TRUE_LITERAL '\x01'
#define JSONB_FALSE_LITERAL '\x02'
Value
JSON values are serialized into MySQL internal String objects. String is a wrpper class that encapsulates simple c char** characters with specific encoding(utf8mb4). The class is declared in /mysql-server/include/sql_string.h, and its definition is in /mysql-server/sql-common/sql_string.cc*, here just paste main parts of the code:
class String
{
char *m_ptr;
size_t m_length;
const CHARSET_INFO *m_charset;
uint32 m_alloced_length; // should be size_t, but kept uint32 for size reasons
bool m_is_alloced;
public:
// constructors and destructor @by chris
// char* pointer manipulating methods @by chris
private:
size_t next_realloc_exp_size(size_t sz);
bool mem_realloc_exp(size_t arg_length);
public:
// buffer manipulating methods, omit details @by chris
void shrink(size_t arg_length);
bool is_allocated() const { return m_is_allocated;}
// operator overriding, omit details @by chris
static void operator delete(void *ptr_arg, size_t size);
static void operator delete(void *, MEM_ROOT *);
String& operator = (const String &s);
char& operator [] (size_t i) const { return m_ptr[i]; }
// string manipulatings, omit details @by chris
// copy methods @by chris
bool copy();
bool copy(const String &s);
bool copy(const char *s, size_t arg_length, const CHARSET_INFO *cs);
// append methods @by chris
bool append(const String &s);
bool append(const char *s);
bool append(LEX_STRING *s);
bool append(Simple_cstring str);
...
Besides the class of String other two classes are declared in sql_string.h for String usage, they are class Simple_cstring and class StringBuffer : public String.
JSON Object
Each filed of a JSON value has a fixed position in a serialized binary string, the structure of a JSON object has te structure(KE is kev entry; VE is value entry;K is key; V is value) form:
value = "count:size:KE1:KE2:…KEn:VE1:VE2:…:VEn:k1:K2:…kn:V1:V2:…:Vn"

- type identifier 0x00(small json object ) or 0x01 (large json object)
- count identifies the number of elements in JSON document. Its type is either of uint16 or uint32 for small and large document
- size follows count, it identifies the value size of document. Same as count, small document will be uint16 and large document uses uint32
- key entries follows size that identifies the offset of each key from the beging of document
- value entries follow the key entries, each entry identifies the offset of each value from the beging of document
- key list follow the value entries, each key stores real key data
- value list store at the end of document, each value stores real data
The sequence of each field in a binary string is also the sequence of maniuplating while MySQL server serializing a JSON document. The implementation is in /mysql-server/sql/json_binary.cc . The core of serialization is implemented in method of serialize_json_value(const Json_dom dom, size_t type_pos, String dest, size_t depth) and is invoked by bool serialize(const Json_dom dom, String dest) .
bool serialize(const Json_dom *dom, String *dest)
{
// Reset the destination buffer.
dest->length(0);
dest->set_charset(&my_charset_bin);
// Reserve space (one byte) for the type identifier.
if (dest->append('\0'))
return true; /* purecov: inspected */
return serialize_json_value(dom, 0, dest, 0) != OK;
}
/**
Serialize a JSON value at the end of the destination string.
Also go back and update the type specifier for the value to specify
the correct type. For top-level documents, the type specifier is
located in the byte right in front of the value. For documents that
are nested within other documents, the type specifier is located in
the value entry portion at the beginning of the parent document.
@param dom the JSON value to serialize
@param type_pos the position of the type specifier to update
@param dest the destination string
@param depth the current nesting level
@return serialization status
*/
static enum_serialization_result
serialize_json_value(const Json_dom *dom, size_t type_pos, String *dest, size_t depth)
{
const size_t start_pos= dest->length();
DBUG_ASSERT(type_pos < start_pos);
enum_serialization_result result;
switch (dom->json_type())
{
case Json_dom::J_ARRAY:
{
const Json_array *array= down_cast<const Json_array*>(dom);
(*dest)[type_pos]= JSONB_TYPE_SMALL_ARRAY;
result= serialize_json_array(array, dest, false, depth);
/*
If the array was too large to fit in the small storage format,
reset the destination buffer and retry with the large storage
format.
Possible future optimization: Analyze size up front and pick the
correct format on the first attempt, so that we don't have to
redo parts of the serialization.
*/
if (result == VALUE_TOO_BIG)
{
dest->length(start_pos);
(*dest)[type_pos]= JSONB_TYPE_LARGE_ARRAY;
result= serialize_json_array(array, dest, true, depth);
}
break;
}
case Json_dom::J_OBJECT:
{
const Json_object *object= down_cast<const Json_object*>(dom);
(*dest)[type_pos]= JSONB_TYPE_SMALL_OBJECT;
result= serialize_json_object(object, dest, false, depth);
/*
If the object was too large to fit in the small storage format,
reset the destination buffer and retry with the large storage
format.
Possible future optimization: Analyze size up front and pick the
correct format on the first attempt, so that we don't have to
redo parts of the serialization.
*/
if (result == VALUE_TOO_BIG)
{
dest->length(start_pos);
(*dest)[type_pos]= JSONB_TYPE_LARGE_OBJECT;
result= serialize_json_object(object, dest, true, depth);
}
break;
}
...
}
}
Below diagram only shows the main process of JSON object serialization, line 48 ~ line 68.
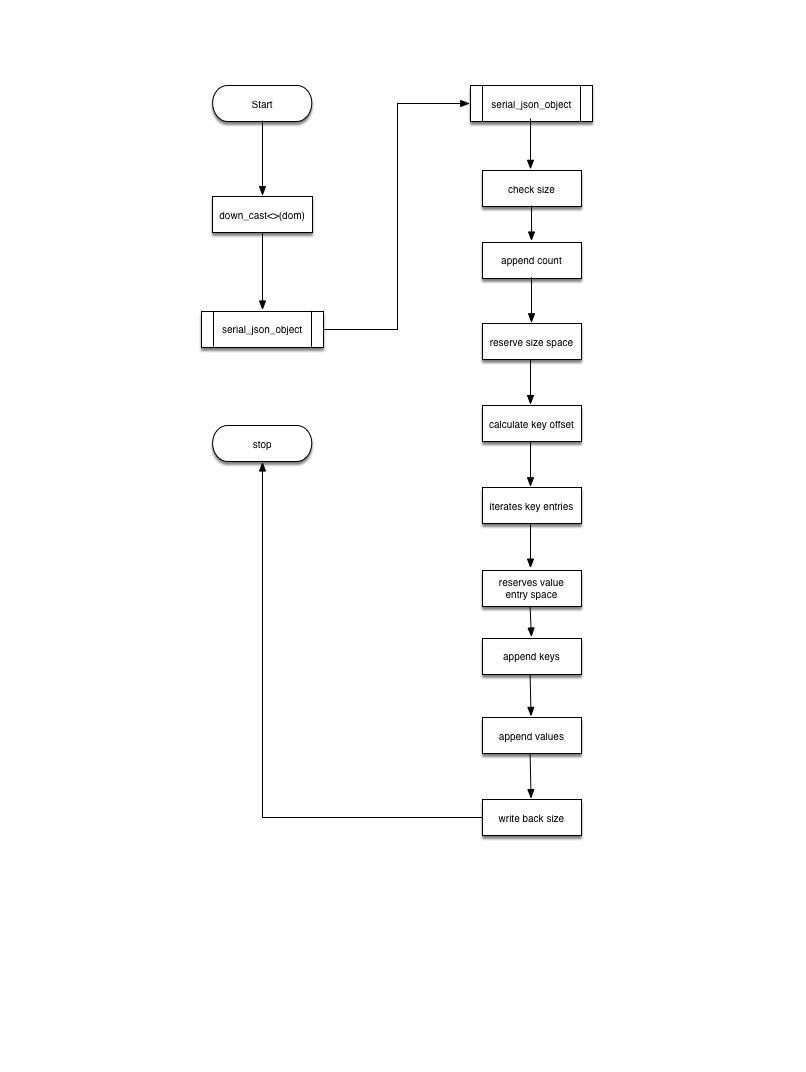
down cast dom object from json_dom to json_object
json_dom is declared in /mysql-server/sql/json_dom.h and json_object is also declared in the header file as one of its subclasses.
down_cast<>() is one template utility method, it uses static_cast to convert one pointer to the one with subclass type safely, because dynamic_cast will result in NULL pointer while peforming down cast. The implementation is defined in /mysql-server/include/template_utils.h
/** Casts from one pointer type to another in a type hierarchy. In debug mode, we verify the cast is indeed legal. */ template<typename Target, typename Source> inline Target down_cast(Source arg) { DBUG_ASSERT(NULL != dynamic_cast<Target>(arg)); return static_cast<Target>(arg); }Set the type identifier as JSON_TYPE_SMALL_OBJECT by using overrided [] operator on String object. As per the implementation of operator [] of String, (\dest)[type_pos] = JSONB_TYPE|_SMALL_OBJECT means set value 0x00 to the the position of type_pos in m_ptr char array. m_ptr is the actual string store of String class. Since the invokation of serialization is return serialize_json_value(dom, 0, dest, 0) != OK; in serialize(Json_dom dom, String dest) method, 0x00 will always stored at offset *0 in String object.
Step 2 was setting type identifier in serialization. Then value serialization should be performed as small object in first try. Here is the source code of serialize_json_object in json_binary.cc.
/** Serialize a JSON object at the end of the destination string. @param object the JSON object to serialize @param dest the destination string @param large if true, the large storage format will be used @param depth the current nesting level @return serialization status */ static enum_serialization_result serialize_json_object(const Json_object *object, String *dest, bool large, size_t depth) { const size_t start_pos= dest->length(); const size_t size= object->cardinality(); if (is_too_big_for_json(size, large)) return VALUE_TOO_BIG; /* purecov: inspected */ // First write the number of members in the object. if (append_offset_or_size(dest, size, large)) return FAILURE; /* purecov: inspected */ // Reserve space for the size of the object in bytes. To be filled in later. const size_t size_pos= dest->length(); if (append_offset_or_size(dest, 0, large)) return FAILURE; /* purecov: inspected */ const size_t key_entry_size= large ? KEY_ENTRY_SIZE_LARGE : KEY_ENTRY_SIZE_SMALL; const size_t value_entry_size= large ? VALUE_ENTRY_SIZE_LARGE : VALUE_ENTRY_SIZE_SMALL; /* Calculate the offset of the first key relative to the start of the object. The first key comes right after the value entries. */ size_t offset= dest->length() + size * (key_entry_size + value_entry_size) - start_pos; #ifndef DBUG_OFF const std::string *prev_key= NULL; #endif // Add the key entries. for (Json_object::const_iterator it= object->begin(); it != object->end(); ++it) { const std::string *key= &it->first; size_t len= key->length(); #ifndef DBUG_OFF // Check that the DOM returns the keys in the correct order. if (prev_key) { DBUG_ASSERT(prev_key->length() <= len); if (len == prev_key->length()) DBUG_ASSERT(memcmp(prev_key->data(), key->data(), len) < 0); } prev_key= key; #endif // We only have two bytes for the key size. Check if the key is too big. if (len > UINT_MAX16) { my_error(ER_JSON_KEY_TOO_BIG, MYF(0)); return FAILURE; } if (is_too_big_for_json(offset, large)) return VALUE_TOO_BIG; /* purecov: inspected */ if (append_offset_or_size(dest, offset, large) || append_int16(dest, static_cast<int16>(len))) return FAILURE; /* purecov: inspected */ offset+= len; } const size_t start_of_value_entries= dest->length(); // Reserve space for the value entries. Will be filled in later. dest->fill(dest->length() + size * value_entry_size, 0); // Add the actual keys. for (Json_object::const_iterator it= object->begin(); it != object->end(); ++it) { if (dest->append(it->first.c_str(), it->first.length())) return FAILURE; /* purecov: inspected */ } // Add the values, and update the value entries accordingly. size_t entry_pos= start_of_value_entries; for (Json_object::const_iterator it= object->begin(); it != object->end(); ++it) { enum_serialization_result res= append_value(dest, it->second, start_pos, entry_pos, large, depth + 1); if (res != OK) return res; entry_pos+= value_entry_size; } // Finally, write the size of the object in bytes. size_t bytes= dest->length() - start_pos; if (is_too_big_for_json(bytes, large)) return VALUE_TOO_BIG; insert_offset_or_size(dest, size_pos, bytes, large); return OK; }
Step 1: Checks if the object is larger than 64KB, if it is then return error of VALUE_TOO_BIG to serialize_json_value() and reset the large flag to true and retries.
Step 2: Appends the count (number of members in object) to the string object
Step 3: Reserves the space of value size to follow count filed set in second step, the actual bytes to reserve is determined by large flag. If it is true then size of uint32 (4 bytes) will be reserved otherwise uint16(2 bytes) to be reserved.
/** Append an offset or a size to a String. @param dest the destination String @param offset_or_size the offset or size to append @param large if true, use the large storage format (4 bytes); otherwise, use the small storage format (2 bytes) @return false if successfully appended, true otherwise */ static bool append_offset_or_size(String *dest, size_t offset_or_size, bool large) { if (large) return append_int32(dest, static_cast<int32>(offset_or_size)); else return append_int16(dest, static_cast<int16>(offset_or_size)); }Step 4: calculates the offset of first key relative to the start of object as per small or large document. The offset calculation uses several offset constants which are defined as macros in json_binary.cc.
/* The size of offset or size fields in the small and the large storage format for JSON objects and JSON arrays. */ #define SMALL_OFFSET_SIZE 2 #define LARGE_OFFSET_SIZE 4 /* The size of key entries for objects when using the small storage format or the large storage format. In the small format it is 4 bytes (2 bytes for key length and 2 bytes for key offset). In the large format it is 6 (2 bytes for length, 4 bytes for offset). */ #define KEY_ENTRY_SIZE_SMALL (2 + SMALL_OFFSET_SIZE) #define KEY_ENTRY_SIZE_LARGE (2 + LARGE_OFFSET_SIZE) /* The size of value entries for objects or arrays. When using the small storage format, the entry size is 3 (1 byte for type, 2 bytes for offset). When using the large storage format, it is 5 (1 byte for type, 4 bytes for offset). */ #define VALUE_ENTRY_SIZE_SMALL (1 + SMALL_OFFSET_SIZE) #define VALUE_ENTRY_SIZE_LARGE (1 + LARGE_OFFSET_SIZE)The offset of first key relative to start of the object is calculated as :const size_t key_entry_size= large ? KEY_ENTRY_SIZE_LARGE : KEY_ENTRY_SIZE_SMALL; const size_t value_entry_size= large ? VALUE_ENTRY_SIZE_LARGE : VALUE_ENTRY_SIZE_SMALL; /* Calculate the offset of the first key relative to the start of the object. The first key comes right after the value entries. */ size_t offset= dest->length() + size * (key_entry_size + value_entry_size) - start_pos;That's to say, first key is following value entries tightly.Step 5: Iterates key entries to append each key offset into string object with key size validation. Only 2 bytes to record key size, so the size should be less than or equal to the maximum value of uint16, aka 65535, 64KB. In fact each key entry is the offset of each key relative to start of object. That's to say the in maximum the last key has an offset of 65535 + [size offset]
Step 6: Reserves the space of value entries with 0 filled
Step 7: Appends real keys by iteration json object
Step 8: Appends real values by iteration on json object and update value entry size which was reserved at step 6
Step 9: Writes back the json object size to string object which was reserved at step 3
JSON Array
JSON array serialzied into string as below diagram. Its structure is simple than JSON object that it has no key entries after serialization( VE is value entry;V is value).
value = "count:size:VE1:VE2:…:VEn:V1:V2:…:Vn"
- type identifier 0x02( small json array) or 0x03 (large json array)
- count uint16 for small json doc/uint32 for large
- size of binary value, uint16 for small json doc/uint32 for large
- value entries the offset of each value relative to start of the array
- values store the real values of each element in json array

The serialization of JSON array is similar as JSON object. I will not go into depth of JSON array.
Others
Not only object and array in the implementation of MySQL JSON document serialization. The others are also implemented in the method of
static enum_serialization_resultserialize_json_value(const Json_dom dom, size_t type_pos, String dest, size_t depth)
includes:
JSON_STRING
JSON_INT
JSON_UINT
JSON_DOUBLE
JSON_NULL
JSON_BOOLEAN
JSON_OPAQUE (custom data types, any data type in MySQL)
JSON_DECIMAL
JSON_DATE, JSON_TIME, JSON_DATETIME, JSON_TIMESTAMP
Most of these types are noraml, except for JSON_OPAQUE. It is used to store the values that could not serialized or deserialized. Aka, the values not an object or array, and not other scalar types(string, number, null, boolean). In MySQL it is represented by class Json_opaque which is declared in /mysql-server/sql/json_dom.h.
/** Represents a MySQL value opaquely, i.e. the Json DOM can not serialize or deserialize these values. This should be used to store values that don't map to the other Json_scalar classes. Using the "to_string" method on such values (via Json_wrapper) will yield a base 64 encoded string tagged with the MySQL type with this syntax: "base64:typeXX:<base 64 encoded value>" */ class Json_opaque : public Json_scalar { private: enum_field_types m_mytype; std::string m_val; public: /** An opaque MySQL value. @param[in] mytype the MySQL type of the value @param[in] v the binary value to be stored in the DOM. A copy is taken. @param[in] size the size of the binary value in bytes @see #enum_field_types @see Class documentation */ Json_opaque(enum_field_types mytype, const char *v, size_t size); ~Json_opaque() {} // See base class documentation enum_json_type json_type() const { return J_OPAQUE; } /** @return a pointer to the opaque value. Use #size() to get its size. */ const char *value() const { return m_val.data(); } /** @return the MySQL type of the value */ enum_field_types type() const { return m_mytype; } /** @return the size in bytes of the value */ size_t size() const { return m_val.size(); } // See base class documentation Json_dom *clone() const; };
Summary
Since the format of serialized JSON document composes type identifer, elment count, value size, key and value offsets and real keys and values, it will be fast to query the document conveniently. The key and value could be retrieved via calculating the offset firstly and then get the data directly with offset.
Deserialization
In the real world blagging is always far more than donating, and this principle is also ruling the world of data. After data created they will be querying again and again, until having no value to producers or consumers. So...deserialization of persisted JSON document is much more import than serialization in the view of performance.
MySQL implement deserialization skillfully by introducing Json_dom representation and based on it building up series of convinent JSON manipulation functions. Besides Json_dom another class Value is declared in namespace of json_binary to store preparsed data from column of JSON. Let's take a look at how to deserialize a persisted JSON document in MySQL.
Json_dom the base class to represent one JSON document in memory and there are series of subclasses of it to represent the sepecific JSON data type. Below diagram shows the the hierarchy of Json_dom.
 As per the diargram, we can see that both of Json_object and Json_array have standard container to store the data. For Json_object it uses one std::map to store the sorted keys and values, and for Json_array it uses one Preallocated_array which is declared in file /mysql-server/include/preallocated_array.h to store all values. For details plz refer /mysql-server/sql/json_dom.h.
As per the diargram, we can see that both of Json_object and Json_array have standard container to store the data. For Json_object it uses one std::map to store the sorted keys and values, and for Json_array it uses one Preallocated_array which is declared in file /mysql-server/include/preallocated_array.h to store all values. For details plz refer /mysql-server/sql/json_dom.h.
Binary string to Value
The first phase parsing binary string flow is shown in below diagram.
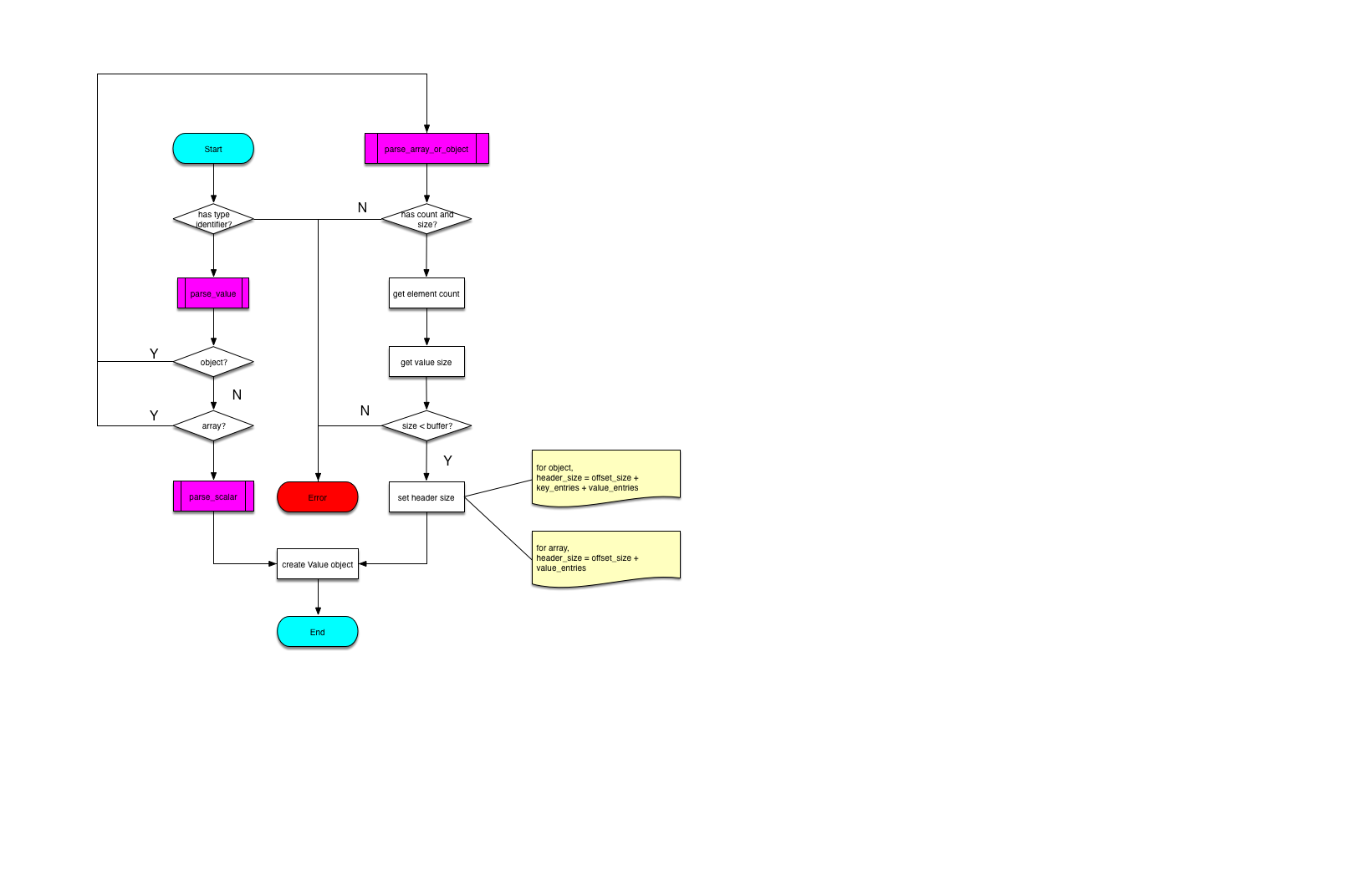
Parsing is splitted into two different subroutines according to the string type. Object and array will be parsed by using parse_array_or_object, compared to scalars(literal, numbers, boolean or null) using parse_scalar.
Then we only check how to parse an JSON object from one binary string.
Parsing Object
Both JSON object and array are parsed by using the static function of static Value parse_array_or_object(Value::enum_type t, const char \data, size_t len, bool large) which is defined in file /mysql-server/sql/sql_binary.cc. This function is consits of *Two parts:
- Calculate the offset of value header
- Create Value instance which will hold the data from binary string
/**
Parse a JSON array or object.
@param t type (either ARRAY or OBJECT)
@param data pointer to the start of the array or object
@param len the maximum number of bytes to read from data
@param large if true, the array or object is stored using the large
storage format; otherwise, it is stored using the small
storage format
@return an object that allows access to the array or object
*/
static Value parse_array_or_object(Value::enum_type t, const char *data,
size_t len, bool large)
{
DBUG_ASSERT(t == Value::ARRAY || t == Value::OBJECT);
/*
Make sure the document is long enough to contain the two length fields
(both number of elements or members, and number of bytes).
*/
const size_t offset_size= large ? LARGE_OFFSET_SIZE : SMALL_OFFSET_SIZE;
if (len < 2 * offset_size)
return err();
const size_t element_count= read_offset_or_size(data, large);
const size_t bytes= read_offset_or_size(data + offset_size, large);
// The value can't have more bytes than what's available in the data buffer.
if (bytes > len)
return err();
/*
Calculate the size of the header. It consists of:
- two length fields
- if it is a JSON object, key entries with pointers to where the keys
are stored
- value entries with pointers to where the actual values are stored
*/
size_t header_size= 2 * offset_size;
if (t == Value::OBJECT)
header_size+= element_count *
(large ? KEY_ENTRY_SIZE_LARGE : KEY_ENTRY_SIZE_SMALL);
header_size+= element_count *
(large ? VALUE_ENTRY_SIZE_LARGE : VALUE_ENTRY_SIZE_SMALL);
// The header should not be larger than the full size of the value.
if (header_size > bytes)
return err(); /* purecov: inspected */
return Value(t, data, bytes, element_count, large);
}
As source code shows, before calculating the header size, the validation of element count and data size are performed firstly as line 21 ~ line 23. MySQL needs to ensure the element count and size are correctly included in the JSON binary string value.
Once the validation passes, element count and size will be retrieved by using the static function of static size_t read_offset_or_size(const char \data, bool large). It is also defined in json_binary.cc*.
/**
Read an offset or size field from a buffer. The offset could be either
a two byte unsigned integer or a four byte unsigned integer.
@param data the buffer to read from
@param large tells if the large or small storage format is used; true
means read four bytes, false means read two bytes
*/
static size_t read_offset_or_size(const char *data, bool large)
{
return large ? uint4korr(data) : uint2korr(data);
}
This function reads an offset either by invoking uint4korr or uint2korr according to the document size. If document size is larger than 64KB the former will be invoked, otherwise the latter will be invoked. uint4korr and uint2korr both are static inline functions defined in /mysql-server/include/byte_order_generic.h. They converts the char* string to one 16bit or 32bit integer via bit shift operations.
static inline uint16 uint2korr(const uchar *A)
{
return
(uint16) (((uint16) (A[0])) +
((uint16) (A[1]) << 8))
;
}
static inline uint32 uint4korr(const uchar *A)
{
return
(uint32) (((uint32) (A[0])) +
(((uint32) (A[1])) << 8) +
(((uint32) (A[2])) << 16) +
(((uint32) (A[3])) << 24))
;
}
After offset and size calculated, one json_binary::Value instance will be created by calling the constructor:
Value(enum_type t, const char *data, size_t element_count, size_t bytes, bool large);
- t is the JSON data type
- \data* is the binary string
- element_count is the count of elements of one JSON object or JSON array
- bytes is the size of binary string
- large is the flag identifying if the object or array is larger than 64KB
The definition is in json_binary.cc.
// Constructor for arrays and objects.
Value::Value(enum_type t, const char *data, size_t bytes,
size_t element_count, bool large)
: m_type(t), m_field_type(), m_data(data), m_element_count(element_count),
m_length(bytes), m_int_value(), m_double_value(), m_large(large)
{
DBUG_ASSERT(t == ARRAY || t == OBJECT);
}
The constructor sets all required fields:
- m_type
- m_data
- m_elment_count
- m_length
- m_large
to the members of *json_binary::Value and then returns to the caller json_dom::parse(json_binary::Value &v) for further processing.
Value to DOM
After json_bianry::Value reference constructured, json_dom::parse(json_binary::Value &v) starts parsing the document via Value reference. This method parses Value reference according to the type of document too. We will only investigate the parse of JSON object to understand its principles.
Json_dom *Json_dom::parse(const json_binary::Value &v)
{
Json_dom *result= NULL;
switch (v.type())
{
case json_binary::Value::OBJECT:
{
std::auto_ptr<Json_object> jo(new (std::nothrow) Json_object());
if (jo.get() == NULL)
return NULL; /* purecov: inspected */
for (uint32 i= 0; i < v.element_count(); ++i)
{
/*
Add the key/value pair. Json_object::add_alias() guarantees
that the value is deallocated if it cannot be added.
*/
if (jo->add_alias(std::string(v.key(i).get_data(),
v.key(i).get_data_length()),
parse(v.element(i))))
{
return NULL; /* purecov: inspected */
}
}
result= jo.release();
break;
}
case json_binary::Value::ARRAY:
{
std::auto_ptr<Json_array> jarr(new (std::nothrow) Json_array());
if (jarr.get() == NULL)
return NULL; /* purecov: inspected */
for (uint32 i= 0; i < v.element_count(); ++i)
{
...
As per the implementation we can see that:
- Firstly one standard smart pointer std::auto_ptr
- Secondly, loops all the elements to invoke bool add_alias(const std::string &key, Json_dom \value) method of Json_object* class.
- Finally, the smart pointer releases the ownership of Json_object instance and make result points to it to return.
We can see that, the key point is to invoke the method of bool add_alias(const std::string &key, Json_dom \value). This method passes in two* temproraly parameters:
- std::string reference with
- return value of v.key(i).get_data()
- return value of v.key(i).get_data_length()
- return value of parse(v.element(i))
That's to say, first parameter is key and the second is the value of the key. The key is a std::string reference which is constructed by v.key(i).get_data() and v.key(i).get_data_length(). Now let's check what will be returned of v.key(i).get_data() and v.key(i).get_data_length().
The method of Value key(size_t pos) const is used to get the key of the member stored at the specified position in a JSON object into json_binary::Value reference. In fact this method gets the key by calculating the offset accordign to the passed in pos parameter. Because all keys are sorted by their length and stored in binary string, it ganrantees that we can get the specific key correctly by passing in the position.
After json_binary::Value& returned, how to get its real characters value? In fact, the real key data is stored in m_data in the json_binary::Value&.
/**
Get a pointer to the beginning of the STRING or OPAQUE data
represented by this instance.
*/
const char *Value::get_data() const
{
DBUG_ASSERT(m_type == STRING || m_type == OPAQUE);
return m_data;
}
/**
Get the length in bytes of the STRING or OPAQUE value represented by
this instance.
*/
size_t Value::get_data_length() const
{
DBUG_ASSERT(m_type == STRING || m_type == OPAQUE);
return m_length;
}
The value is of given key is retrieved by calling v.element(i). What's the logic of method json_binary::Value::Value element(size_t pos)? Below code could be referred to digg the details. In fact, the logic is to get the offset of the value and then invoke parse_value method to parse the bianary string with offsets.
/**
Get the element at the specified position of a JSON array or a JSON
object. When called on a JSON object, it returns the value
associated with the key returned by key(pos).
@param pos the index of the element
@return a value representing the specified element, or a value where
type() returns ERROR if pos does not point to an element
*/
Value Value::element(size_t pos) const
{
DBUG_ASSERT(m_type == ARRAY || m_type == OBJECT);
if (pos >= m_element_count)
return err();
/*
Value entries come after the two length fields if it's an array, or
after the two length fields and all the key entries if it's an object.
*/
size_t first_entry_offset=
2 * (m_large ? LARGE_OFFSET_SIZE : SMALL_OFFSET_SIZE);
if (type() == OBJECT)
first_entry_offset+=
m_element_count * (m_large ? KEY_ENTRY_SIZE_LARGE : KEY_ENTRY_SIZE_SMALL);
const size_t entry_size=
m_large ? VALUE_ENTRY_SIZE_LARGE : VALUE_ENTRY_SIZE_SMALL;
const size_t entry_offset= first_entry_offset + entry_size * pos;
uint8 type= m_data[entry_offset];
/*
Check if this is an inlined scalar value. If so, return it.
The scalar will be inlined just after the byte that identifies the
type, so it's found on entry_offset + 1.
*/
if (type == JSONB_TYPE_INT16 || type == JSONB_TYPE_UINT16 ||
type == JSONB_TYPE_LITERAL ||
(m_large && (type == JSONB_TYPE_INT32 || type == JSONB_TYPE_UINT32)))
return parse_scalar(type, m_data + entry_offset + 1, entry_size - 1);
/*
Otherwise, it's a non-inlined value, and the offset to where the value
is stored, can be found right after the type byte in the entry.
*/
size_t value_offset= read_offset_or_size(m_data + entry_offset + 1, m_large);
if (m_length < value_offset)
return err(); /* purecov: inspected */
return parse_value(type, m_data + value_offset, m_length - value_offset);
}
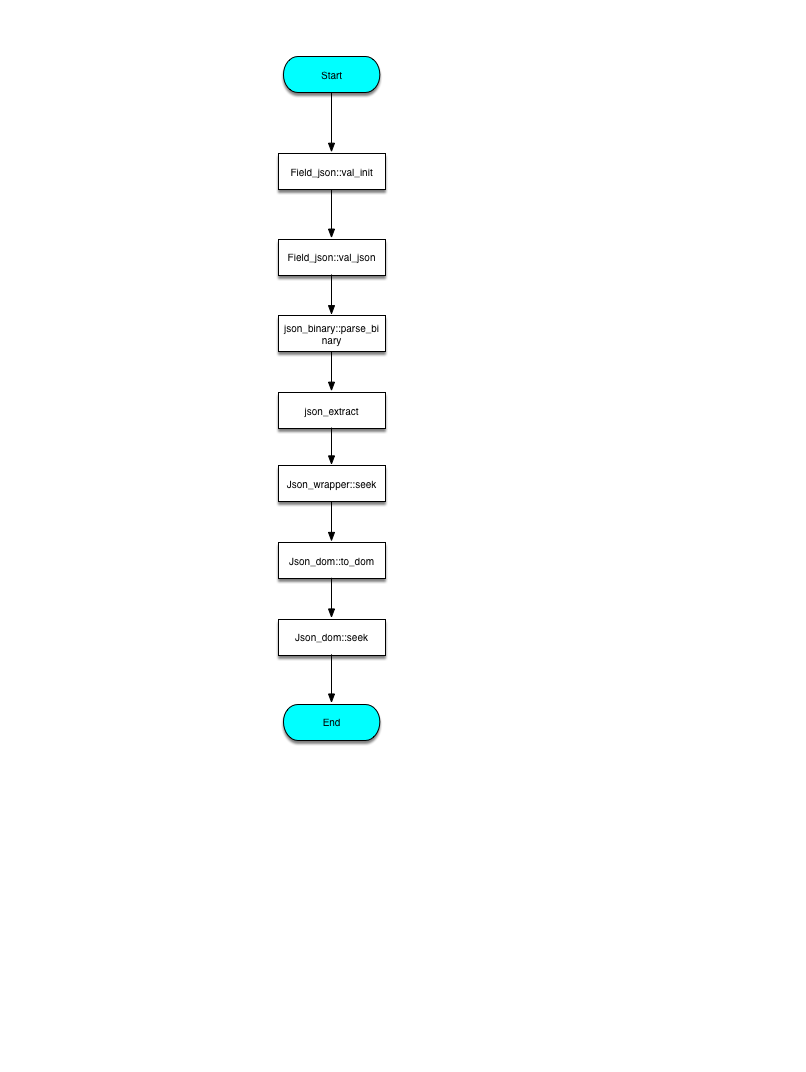
After analyzing the deserialization of bianary string, let's build up a full complete view of JSON document deserialzation by investigating how does json_extract function works.
Full view
In this part we will not deep into the details of json_extract, but only focus on the work flow of deserialization in the view of SQL statement execution in MySQL server side.
Before analyze the work flow of json_extract or doc->'$.path' we need to know about the SQL statement execution result representation in MySQL server side. Below UML diagram shows the hierarchy of MySQL server SQL statement execution result of functions. I only summarize some of the functions here, the blue colored functions are mostly used in our service development.
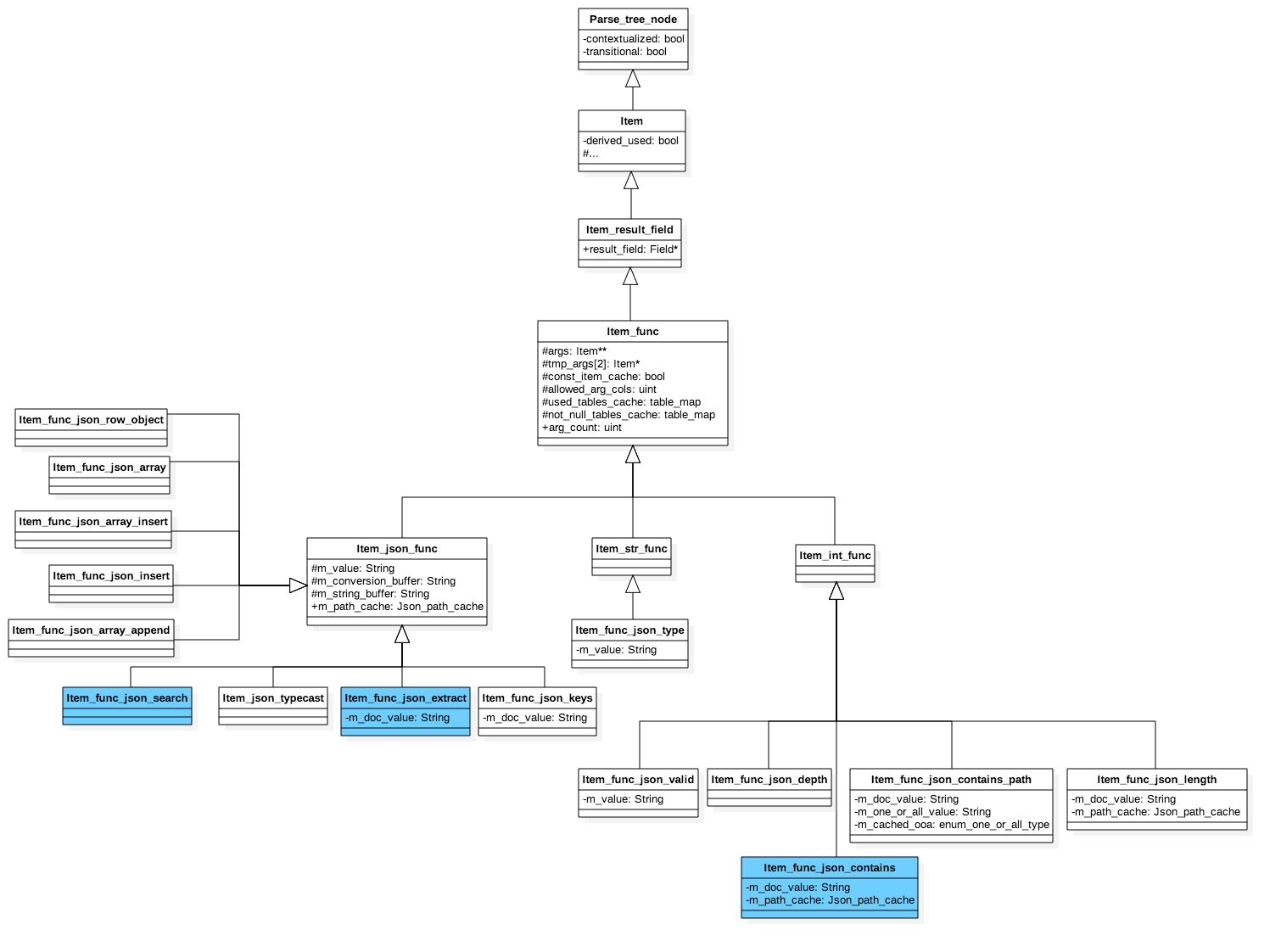
As you can see, the native json functions of MySQL are all subclasses of class Item_func, each native function has its owner class in the server side implmentation. Here we analyze the full flow of json_extract by digging the source code of class Item_func_json_extract which is defined in /mysql-server/sql/item_json_func.h.
/**
Represents the JSON function JSON_EXTRACT()
*/
class Item_func_json_extract :public Item_json_func
{
String m_doc_value;
public:
Item_func_json_extract(THD *thd, const POS &pos, PT_item_list *a)
: Item_json_func(thd, pos, a)
{}
Item_func_json_extract(THD *thd, const POS &pos, Item *a, Item *b)
: Item_json_func(thd, pos, a, b)
{}
const char *func_name() const
{
return "json_extract";
}
bool val_json(Json_wrapper *wr);
};
May be you're supprising the class is so simple, we only need to investigate the method of bool val_json(Json_wrapper \wr). In fact, this method is the ONE we are seeking. It is defined in the implementation file /mysql-server/sql/item_json_func.cc*
bool Item_func_json_extract::val_json(Json_wrapper *wr)
{
DBUG_ASSERT(fixed == 1);
try
{
Json_wrapper w;
// multiple paths means multiple possible matches
bool could_return_multiple_matches= (arg_count > 2);
// collect results here
Json_wrapper_vector v(key_memory_JSON);
if (get_json_wrapper(args, 0, &m_doc_value, func_name(), &w))
return error_json();
if (args[0]->null_value)
{
null_value= true;
return false;
}
for (uint32 i= 1; i < arg_count; ++i)
{
if (m_path_cache.parse_and_cache_path(args, i, false))
{
null_value= true;
return false;
}
Json_path *path= m_path_cache.get_path(i);
if (path->contains_wildcard_or_ellipsis())
{
could_return_multiple_matches= true;
}
if (w.seek(*path, &v, true, false))
return error_json(); /* purecov: inspected */
}
if (v.size() == 0)
{
null_value= true;
return false;
}
else if (could_return_multiple_matches)
{
Json_array *a= new (std::nothrow) Json_array();
if (!a)
return error_json(); /* purecov: inspected */
for (Json_wrapper_vector::iterator it= v.begin(); it != v.end(); ++it)
{
if (a->append_clone(it->to_dom()))
{
delete a; /* purecov: inspected */
return error_json(); /* purecov: inspected */
}
}
Json_wrapper w(a);
wr->steal(&w);
}
else // one path, no ellipsis or wildcard
{
// there should only be one match
DBUG_ASSERT(v.size() == 1);
wr->steal(&v[0]);
}
} CATCH_ALL("json_extract", return error_json()) /* purecov: inspected */
null_value= false;
return false;
This method is a bit complex, but we won't need to make every bit clear. Since we just want to understand how does MySQL server deserialize the JSON document. So looking back to the source code, you will find out that line 38 is bright! It invokes the method: bool Json_wrapper::seek( const Json_seekable_path &path, Json_wrapper_vector \hits, bool auto_wrap,bool only_need_one)*
About the class Json_wrapper we will not expand it here. For details please refer /mysql-server/sql/json_dom.h. It wrapps one Json_dom instance and it is a subclass of Sql_alloc. Let's check the source code of this method:
bool Json_wrapper::seek(const Json_seekable_path &path,
Json_wrapper_vector *hits,
bool auto_wrap, bool only_need_one)
{
if (empty())
{
/* purecov: begin inspected */
DBUG_ABORT();
return false;
/* purecov: end */
}
// use fast-track code if the path doesn't have any ellipses
if (!path.contains_ellipsis())
{
return seek_no_ellipsis(path, hits, 0, auto_wrap, only_need_one);
}
/*
FIXME.
Materialize the dom if the path contains ellipses. Duplicate
detection is difficult on binary values.
*/
to_dom();
Json_dom_vector dhits(key_memory_JSON);
if (m_dom_value->seek(path, &dhits, auto_wrap, only_need_one))
return true; /* purecov: inspected */
for (Json_dom_vector::iterator it= dhits.begin(); it != dhits.end(); ++it)
{
Json_wrapper clone((*it)->clone());
if (clone.empty() || hits->push_back(Json_wrapper()))
return true; /* purecov: inspected */
hits->back().steal(&clone);
}
return false;
}
The key point is line 25 and line 28. The former calls method to_dom() of Json_dom:
Json_dom *Json_wrapper::to_dom()
{
if (!m_is_dom)
{
// Build a DOM from the binary JSON value and
// convert this wrapper to hold the DOM instead
m_dom_value= Json_dom::parse(m_value);
m_is_dom= true;
m_dom_alias= false;
}
return m_dom_value;
}
Line 7: m_dom_value = Json_dom::parse(m_value) is very important. m_value is a filed of Json_wrapper, its type is .... json_binary::Value, where is it from??? This value is initialized at the very beginng of field query statment, such as :
longlong Field_json::val_int()
{
ASSERT_COLUMN_MARKED_FOR_READ;
Json_wrapper wr;
if (is_null() || val_json(&wr))
return 0; /* purecov: inspected */
return wr.coerce_int(field_name);
}
bool Field_json::val_json(Json_wrapper *wr)
{
ASSERT_COLUMN_MARKED_FOR_READ;
DBUG_ASSERT(!is_null());
String tmp;
String *s= Field_blob::val_str(&tmp, &tmp);
/*
The empty string is not a valid JSON binary representation, so we
should have returned an error. However, sometimes an empty
Field_json object is created in order to retrieve meta-data.
Return a dummy value instead of raising an error. Bug#21104470.
The field could also contain an empty string after forcing NULL or
DEFAULT into a not nullable JSON column using lax error checking
(such as INSERT IGNORE or non-strict SQL mode). The JSON null
literal is used to represent the empty value in this case.
Bug#21437989.
*/
if (s->length() == 0)
{
Json_wrapper w(new (std::nothrow) Json_null());
wr->steal(&w);
return false;
}
json_binary::Value v(json_binary::parse_binary(s->ptr(), s->length()));
if (v.type() == json_binary::Value::ERROR)
{
/* purecov: begin inspected */
my_error(ER_INVALID_JSON_BINARY_DATA, MYF(0));
return true;
/* purecov: end */
}
Json_wrapper w(v);
wr->steal(&w);
return false;
}
Line 38 will invoke the json_binary::parse_binary method to parse origin passed in JSON dcoument with path. Then use the value to init the Json_wrapper instance. That's where the m_value comes from.
Now let's back to the Json_wrapper::seek method process after to_dom(). After DOM instance created, invoking the seek method of Json_dom to find the actual data and then push to Json_wrapper_vector.
This is the overall process of querying one JSON document with json_extract, eg. SELECT json_extract(option->path) FROM coupon;
By now, we can summarize the overall flow of deserialization of JSON document in below diagram.