缩略图优化
0x1 城市里来了新长官
这里要讲的故事说起来真是历史有悠久了,那时候,还是曾经的硅谷明星Hewleet-Packard,现在一切都变了,老家伙们(IBM、HP)被这个时代狠狠的抛弃了,迈克尔-记录哪里都有我-乔丹曾经对魔术师约翰逊和大鸟伯德喷了一句著名的垃圾话:”城市里来了新长官!“。恩,时代变了大家都得接受现实。
其实,并不是这个世界变化太快,而是老家伙们的动作实在太慢,慢的老天都看不下去了,只好迫使他们在来不及思考的情况下去做一些仓促的选择。公司如此,我们这些80后老家伙似乎更甚。码农界的80后们现在都已日渐苍老,更可怕的是各种新事物还在不断涌现,令人应接不暇。这架势令人很迷茫,似乎如果你现在不会一点AI(吹)、BigData(牛)和Cloud(逼)就是个码农怪胎,除了害人拉低公司水平好像没有其它价值。
0x2 背景
在HP时候做的项目HP Connected Drive(HPCD)是一个类似于Dropbox的服务,可以让用户在PC、平板以及手机上共享图片、文档和视频等文件。这个项目是HP当年打造PC生态的一个尝试,不过随着windows 10的出现,这个项目也就不得不退出历史舞台了。HPCD的后台部署在当时HP仍然大力推广的HP Helion公有云上,其核心存储正是Openstack平台中的Swift对象存储系统,几乎所有的文件操作都是通过Swift存储完成的。虽然Swift帮助系统解决了可用性和分布式问题,但是这个世界上所有的硬币都有正反面,很显然Swift也不能幸免,在带来好处的同时也带着弊端。由于Swift自身的account,container和object三层逻辑结构以及网络带宽等等各种因素造成用户在上传文件之后设备上同步显示缩略图(thumbnail)的性能太差,在中国团队慢慢接手主要功能开发之后我们亟需通过优化这个弊端来让US的同事们在开会的时候少叨叨叨。
0x3 包袱
下面这张图是原始的缩略图处理的简化架构,主要由三部分组成:
- 文件处理(上传、下载)
- 缩略图处理(上传、下载、裁剪)
- 元数据管理
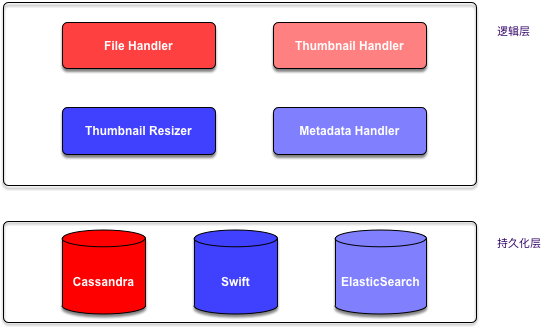
这个架构看上去貌似还凑合,但是在出现大量文件上传时会出现严重的性能问题----缩略图处理中的上传速度太慢,导致并发进行的元数据上传成功后却无缩略图可以下载到客户端展示。文件上传的处理流程由下列几个步骤组成:
- 客户端上传原始缩略图,服务端将其暂存于Swift中
- 服务端从Swift中删除旧的缩略图
- 服务端处理原始缩略图
- 从Swift下载原始缩略图
- 解密原始缩略图
- 根据缩略图配置,裁剪生成不同分辨率的新缩略图文件
- 将所有新生成的缩略图文件上传到Swift中
- 更新元数据中的”has_thumbnail"字段
- 从Swift中删除原始缩略图
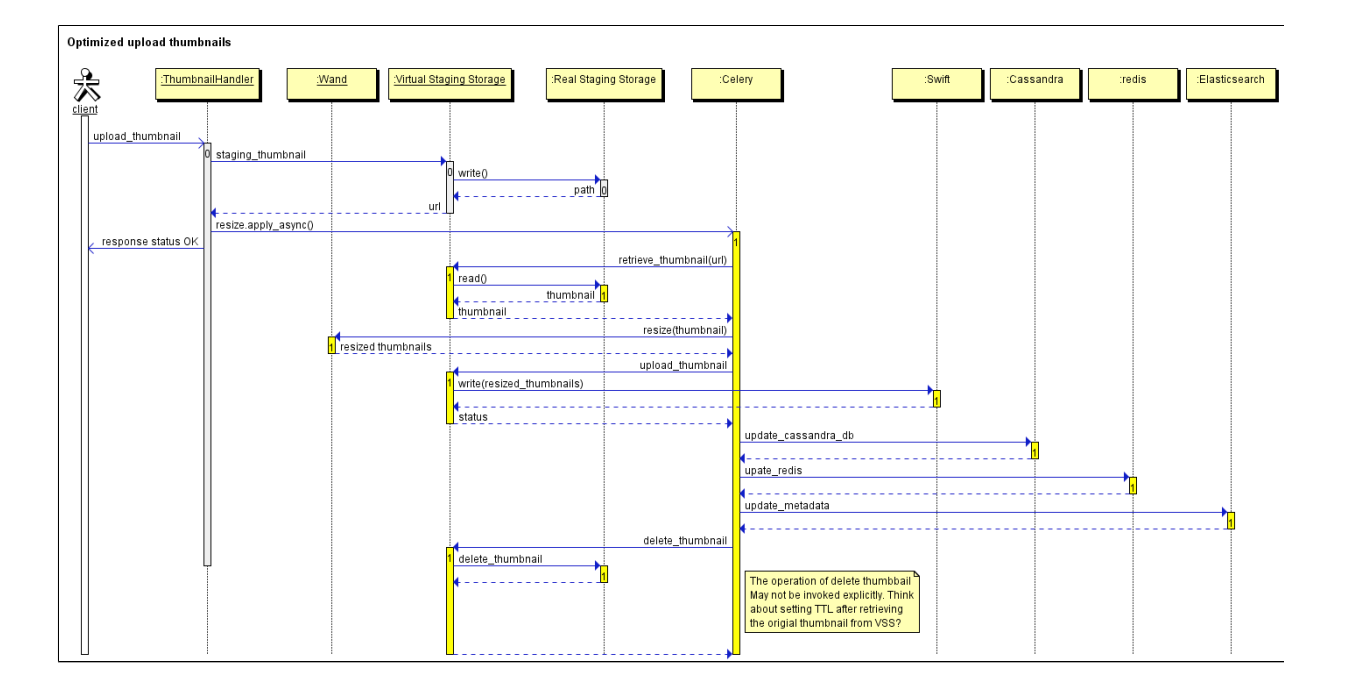
整个流程的sequence flow大致如下图所示:
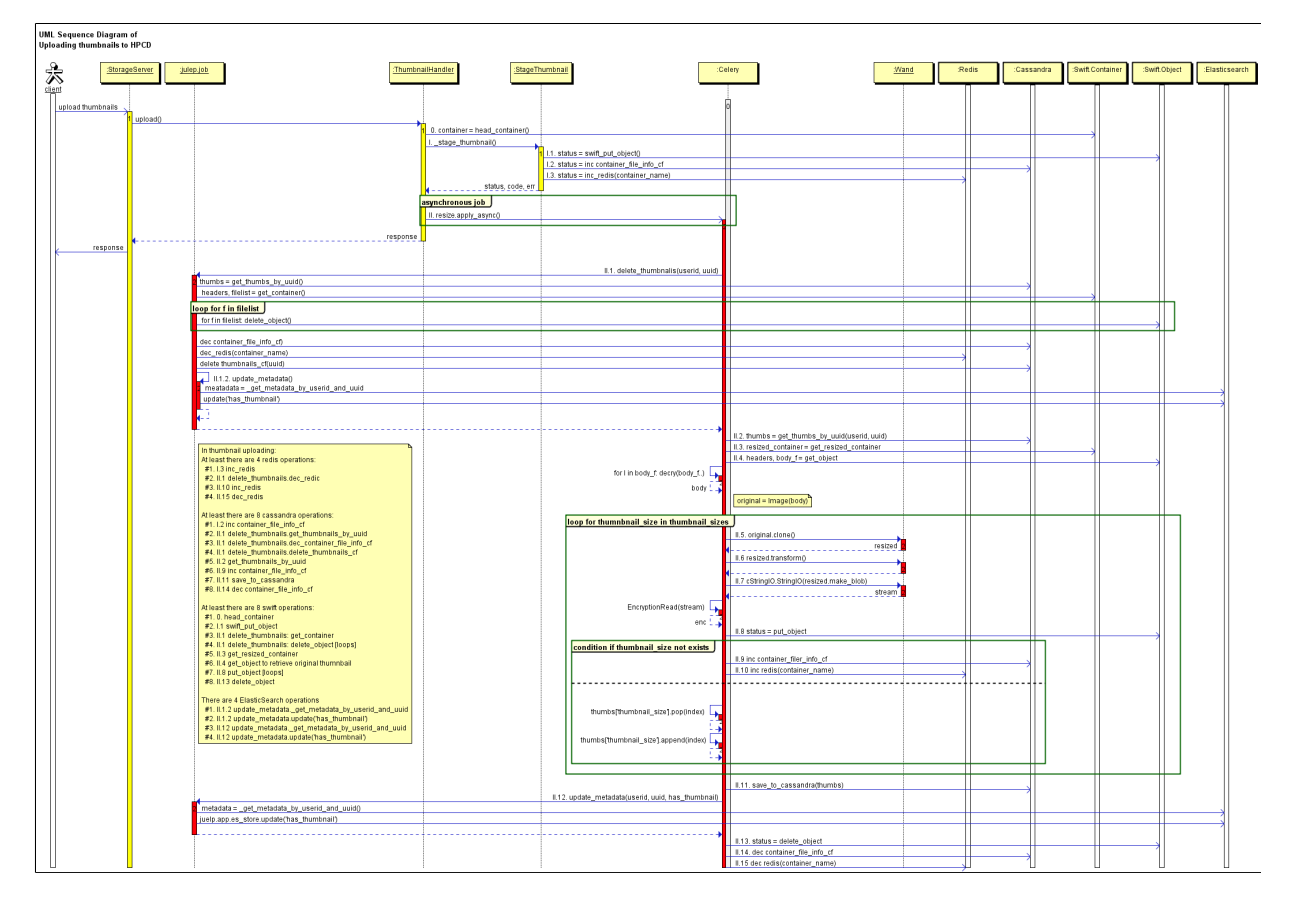
其实系统在设计之初还是考虑到了缩略图处理的负载,因此将原始缩略图的生成工作放在了客户端进行,但是然并卵,这6个步骤有4步是和Swift通信(第2步、第3步、第5步和第6步),严重拉低了系统性能,导致平均每个缩略图的处理时间达到了1000ms左右。下面的表格是在Dev Int和QA环境中实测出来的数据:
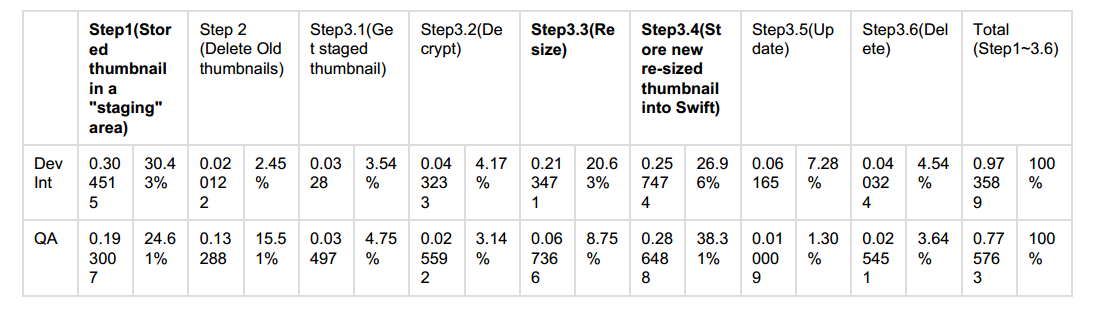
根据流程以及表格中的数据我们可以看出缩略图的处理过程中存在以下诸多问题:
- 网络交互过多(细节未画出)
- 4次Redis操作
- 至少8次Cassandra操作
- 至少8次Swift操作
- 4次Elasticsearch操作
- 缩略图裁剪操作非常耗时
- 重复的Swift操作
- 原始缩略图先暂存到Swift中,然后下载下来进行裁剪,最后再删除Swift中暂存的原始缩略图
- 依赖Celery队列操作
- 代码中的细节问题
很明显,原始缩略图的暂存以及裁剪操作是最耗时的两步,如何优化也就有了思路。由于缩略图裁剪采用的是wand处理库,我们又缺乏足够的图像处理经验,一时难以找到更优的图形库,因此第一阶段就把优化的重心放在了原始缩略图的暂存步骤中。
0x4 军刀
为了解决原始缩略图的暂存问题,我在设计方案时假借了Linux文件系统中的VFS概念,引入了一个抽象的Staging Storage Layer(SSL)层以及抽象的持久化层,用这个抽象层封装所有的IO操作,对API层屏蔽IO细节,并将优化的工作放置在SSL中完成。最初设计时考虑了下面三种需求:
- 将文件存储在本地文件系统中
- 将文件存储在分布式文件系统中
- 将文件存储在分布式缓存中
按照这个设计思路,新的架构就变成下面这个模样了
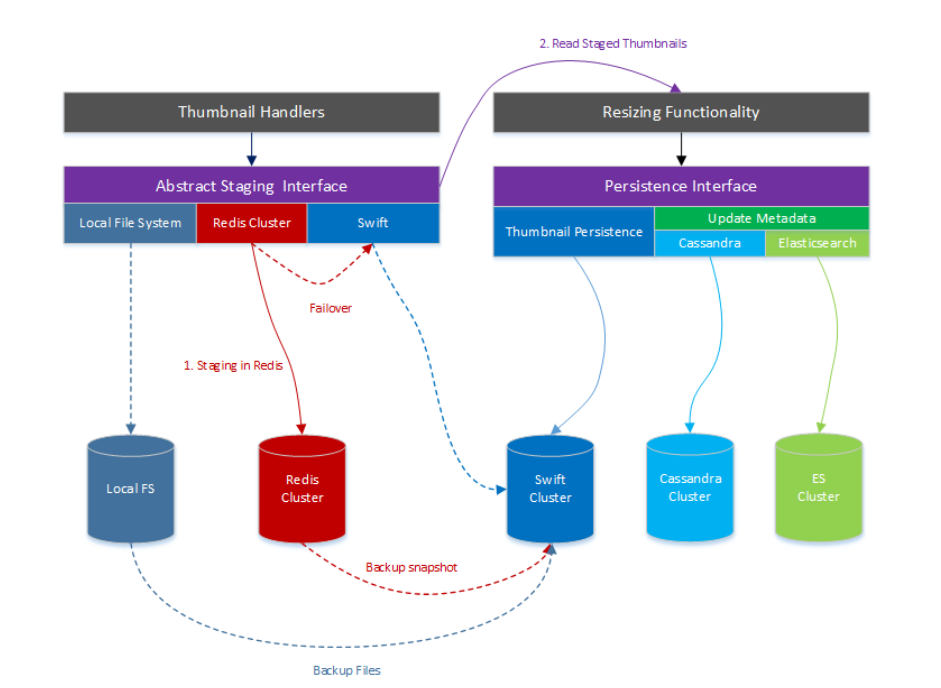
这个架构中最主要引入了Redis作为原始缩略图的暂存场所,也正是这一改动直接将原始缩略图的上传操作从200ms左右降低到5ms左右,一举干掉了第一个瓶颈。新的暂存层提供了以下几个接口:
- 标准的write接口,用于上传文件
- 标准的read接口,用于下载文件
- 标准的remove接口,用于删除暂存文件
- 内部failvoer接口,用于处理失效情况
持久化层则提供下列接口:
- 标准的write接口,用于上传文件
- 标准的metada接口用于上传和下载元数据
经过这个改动,原来的thumbnail处理流程就变成了下面的形式:
- 通过SSL层的write接口暂存原始缩略图
- 通过SSL层的read接口下载原始缩略图
- 使用Wand库裁剪缩略图
- 通过持久化层的write接口上传裁剪后的缩略图
- 通过持SSL层的delete接口删除裁剪完成的原始缩略图
经过优化之后的sequence flow大致如下图所示:
0x5 牛刀
新的设计方案中引入了Redis作为原始缩略图的暂存空间,由于Redis本身的持久化特征(一旦Redis服务器崩溃,极端情况下可能会出现1s的数据丢失),特别引入了可信队列作为Redis中的数据存储结构。可信队列由两个不同的Redis列表存储key值,一个Hash set存储键-值数据,即:
- 临时队列(pending queue)
- 工作队列(working queue)
- 散列集(hash set)
因为在HPCD中采用userId标识用户信息,uuid来标识缩略图信息,因此可信队列的数据接口看起来和下图差不多:
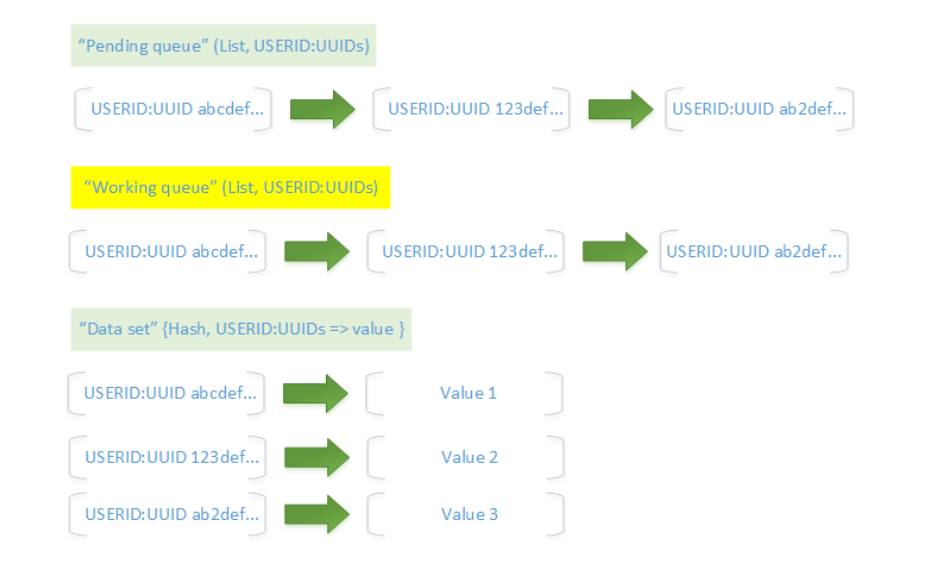
原始缩略图首先存储在临时队列中,当Celery任务开始执行裁剪操作时,将缩略图出队的同时,拷贝副本存储在工作队列中(该操作采用RedisRPOPLPUSH命令完成,是一个原子操作),在裁剪操作完成之后再清理工作队列中的数据。
0x6 提升
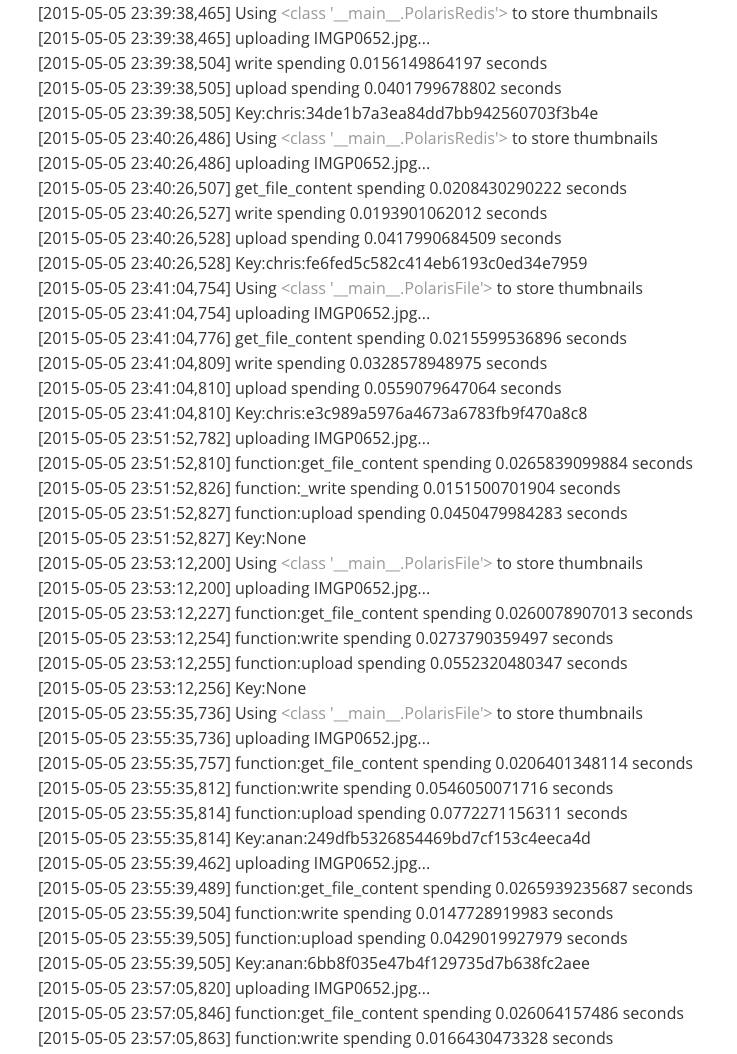
通过优化,原始缩略图的上传时间缩短到了15毫秒左右,提升幅度达到90%以上。下面的数据是在我自己的开发机上测试的结果(IMGP0652.jpg的大小位8.4MB):
0x7 思考
虽然引入一个抽象的虚拟暂存层负责原始缩略图的暂存,显著降低了缩略图的处理时间,但是我们还是需要考虑在Openstack环境中如何scale out暂存层以及如何减少缩略图处理对Celery队列的依赖性。因为在Openstack环境中部署scale out暂存层就需要额外申请虚拟机资源并部署新的redis服务,这一件事就需要层层申请,要做到让boss满意,boss的boss满意等等等等。
关于Celery队列问题比较复杂,原有方案中缩略图的裁剪是一个celery异步job,其性能依赖于Celery和RabbitMQ的整体性能,已知的问题有以下几个方面:
- 缩略图裁剪是一个异步的Celery任务
- 缩略图裁剪任务和其他任务共享同一个消息队列
- 消息可能会在队列中驻留较长时间,甚至出现过大于500秒的情况
- Celery自身的bug引起的死锁问题
上述几个问题也是后续第二阶段需要解决的,但是,世事难料,当第一阶段的工作刚刚开发结束进入测试阶段时,HPCD这个项目就被新上任的VP给cancel了,那么,一切都安静了。