缓存方案设计
@2015.11.15
公司的业务主要有两块构成,分别是面向终端普通用户的2C屌丝理财业务,以及面向中高端客户的2B基金理财业务。其中基金理财业务并不直接面向普通用户开放,而是通过理财师(黄牛/中介)作为掮客完成交易的。不同的业务有不同的需求,2C业务包括完整的下单、支付和清结算流程;而2B业务目前不包括支付和清结算业务,所有现金流都是通过线下完成。在涉及系统架构时考虑到2C业务涉及到完整的流程链,为了远大(虚幻的?)的理想,为了防止系统上线时会像淘宝“双十一”一样嗨爆了,在系统设计之初就引入了缓存系统。虽然业务增长就像一根系数极小的抛物线,但是在设计时我们还是考虑到了各种可能需要冲击后台数据库的情况,比如:
- Session
- Auth令牌
- 图形验证码
- OTP验证码
- 理财产品热销榜
- 热门产品推荐榜
- 理财产品列表
- 等等
实际开发中除了上述业务场景用到了缓存,营销业务也非常不识相的插了一杠,主要用在营销业务中的抽奖和优惠券发放系统中。
Redis vs Memecached
既然缓存是用于提高性能,增强系统的健壮性和可用性的,那么在设计系统缓存方案时,我们就需要慎重考虑以下各个方面的问题:
- 扩展性(scale up/out)
- 读/写性能
- 内存占用率
- 数据持久化
- 是否开源(收费)
这些需要考虑的不同点在不同的系统中占据不同的优势地位,因此在实际开发中我们需要根据优先级来确定适合业务需求的方案。
扩展性
网站后台系统的整体结构采用微服务架构搭建,因此自然就要求缓存系统必须具备很好的扩展性。系统缓存通常具有两种不同的基本形态:
- 共享的缓存集群
- 独占的缓存实例
其中共享的缓存集群很好的满足了当前主流的微服务分布式架构对缓存的需求。这个世界有白天也有黑夜,有男人也有女人,有高富帅也有矮矬穷,每个人每个事物都有自己的定位。网站也不例外,有后台就有前端,有服务就有客户,基于角色逻辑的不同定位,在后台数据落点的分配也就会有不同的途径来实现了。
- 由客户端负责实现数据分片
- 由缓存系统负责实现数据分片
前者的典型拥趸是大名鼎鼎的memecached,而后者目前最流行的就是redis了。而我们的方案也是这两者之间经过比较之后选定的。
memcached
memecached是怎样实现数据分区的呢?为了使系统设计足够简单并获得更高的性能,memcached并未实现分布式集群功能,因为如果用户想让数据分布到不同的memcached实例中,需要通过在客户端利用一定的数据分配算法来将数据分配到不同的实例中。也就是说memcached是不管你数据怎么分配的,它只负责以尽可能快的速度帮你存取数据,而不管你的数据是什么,从哪里来,要到何方去。这里盗了一张图正好展示了memcached的数据是如何分片的了:
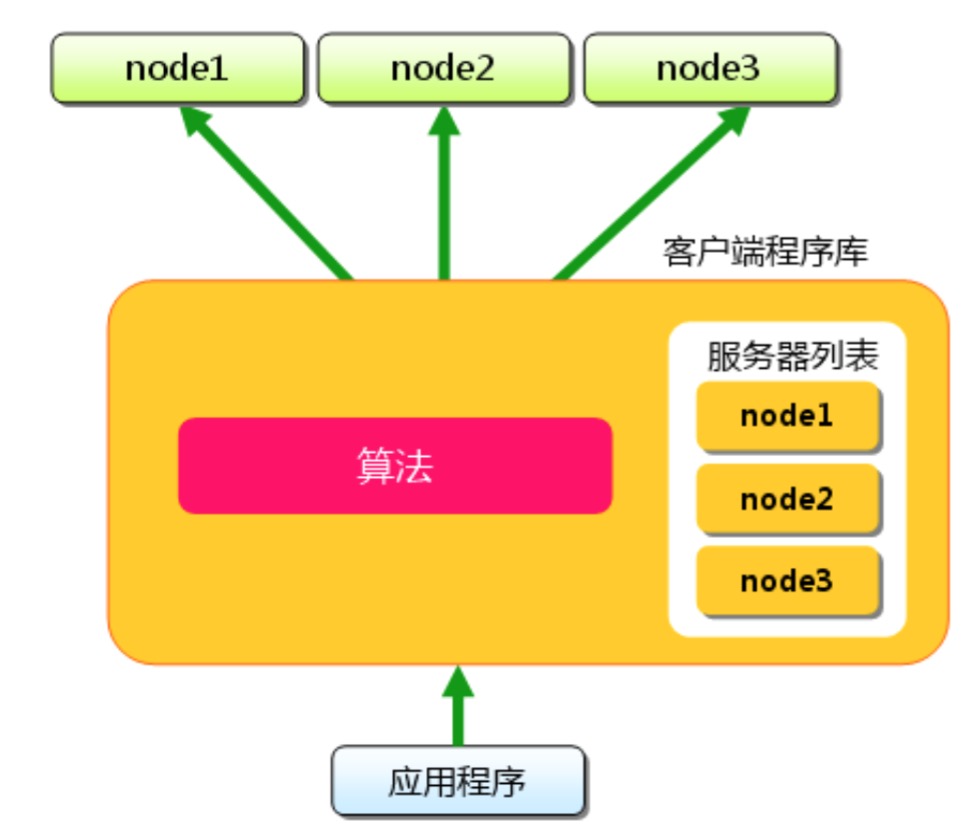
也就是说当某台应用程序服务器接收到一条请求时,服务器要用自己的算法去找到数据缓存的存取节点,算法依赖的是缓存数据的key,比如最简单的模运算分片算法:根据数据的key计算CRC校验码,然后对其进行模运算获得memcached实例的节点。上帝是公平的。你的算法简单也就意味着复杂度可能隐藏在其它方面,比如:目标节点处于失效状态,如果是一个写操作就可能需要进行额外的rehash操作,将数据分配到另一个可用节点中;如果是读操作,这时候可能就得越过缓存直接去数据库读数据了。这里一旦进行rehash就会出现失效节点上全部数据的重分配问题,这样会导致严重的效率问题。基于效率的考虑,出现了更好的一致性哈希算法,通过将数据与缓存节点的散列值统一分配在一个环形空间中的方案,减少由于节点失效或者新增节点引发的大规模数据迁移问题。一致性哈希算法目前在大量的分布式环境中使用,包括OpenStack种的对象存储模块swift下图展示了一致性哈希的环状空间:
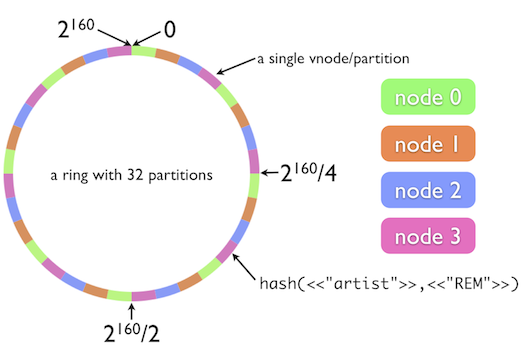
简单来说,在一致性哈希环中每个节点都和数据一起共享键空间,在环中占有一个位置。假设我们有4个节点A、B、C、D组成一个哈希环,每个节点的哈希值分别是(0,100,200,500)。当服务器收到数据存取请求时,根据模运算计算出来的结果在将请求落在环空间中比数据键值大的第一个节点上,例如假设某个数据的散列值是125,那么它就落在节点C上(散列值为200)。与普通的模运算的主要区别就是数据只落在散列值比自己大的节点上。
但是当系统新增一个节点E呢?怎样出来保证数据整体分布的均匀?这时候哈希环就有用了!首先新节点也会在环空间中占有一个位置,假设其散列值为400,原来散列值在200到500之间的数据是都存在节点D上的。这时候中间来了个新节点400,那么影响哪些数据呢?散列值在200-400之间的数据会从D节点搬到新的E节点中,而401-500之间的数则原地不动,继续留在D节点上,这大大减少了数据的迁移量。
redis
redis在3.0之前也不支持原生的数据分区,集群功能需要通过redis sentinel和代理一起配合完成。在redis 3.0发布之后,原生的集群功能终于姗姗来迟,不过似乎在实际使用中任然有不少坑要踩。关于redis分区的详细描述参见redis-集群。
其他
除了扩展性,其他方面的比较用表格列出来,这样比较清晰。
| memcached | redis | |
|---|---|---|
| 扩展性 | 客户端自行处理 | - 3.0以前通过代理+sentinel - 3.0以后支持原生集群 |
| 读/写性能 | 快 | 快,稍慢于memcached |
| 内存占用 | - 可以指定缓存大小 - 即使键过期也无法回收内存空间 |
- 可以指定缓存大小 - 自动回收内存空间 |
| 持久化 | 不支持,需要第三方工具 | - AOF - RDB file |
| 开源 | 是 | 是 |
除了上述表格中列举的总结性对比,memecached还有如下诸多限制:
- 值的大小最大不超过1MB
- 数据类型简单,仅支持简单的键值对类型
- 采用LRU最近最少使用算法更新缓存策略,业务场景单一
- 命令集简单,其支持的命令如下表所示:
| 命令 | 操作 | 命令类型 |
|---|---|---|
| set | 存储数据,若键重复则覆写旧数据,新数据处于LRU顶层 | 写命令 |
| add | 存储数据,仅键不存在时写入数据,新数据处于LRU顶层;若数据已存在,则将旧数据提升到LRU顶层 | 写命令 |
| replace | 存储数据,仅当键存在时写入数据(很少使用,仅为了协议的完备性) | 写命令 |
| append | 尾部追加数据,向已有的键值的末尾添加数据,不能超过数据长度限制 | 写命令 |
| prepend | 头部追加数据,和append相似,区别是在已有键值的头部添加数据 | 写命令 |
| cas | 检查并设置数据(比较与交换),仅对最近一次读之后未被其他更新操作写过的键写入数据,用于竞争条件下并发更新数据 | 写命令 |
| get | 读取数据,可以对一个或多个键发起数据读取请求 | 读命令 |
| gets | 与cas命令配合使用的get命令,与数据一起返回一个64比特数字的CAS标识符,在使用cas命令时若CAS标识符被修改,将不会写入数据 | 读命令 |
| delete | 从缓存中移除键,仅当数据存在时移除 | 写命令 |
| incr/decr | 自增/自减,对一个以64比特整数存储的字符串操作来更高数字,参数只能为正整数。若key不存在,执行失败 | 写命令 |
| stats | 基本的统计信息 | 统计命令 |
| stats items | 关于存储在memcached中的键值信息,以slab为单位分隔 | 统计命令 |
| stats slabs | 比stats items返回的信息更详细,对性能相关的数据更多,以slab为单位分隔 | 统计命令 |
| stats sizes | 展示若采用32字节chunk替代当前的slab数,数据是如何分布的,用于确定slab大小的效率(处于开发中的命令) | 统计命令 |
| flush_all | 使所有数据失效,带有可选的参数用于表示操作可以延迟多少秒。该命令仅仅是将所有键设置过期,并不会释放内存,也不会导致服务器中断 | 统计命令 |
与memcached相比,redis支持的命令和数据结构简直太丰富了,几乎囊括了我们所需要的所有数据结构与形式。redis支持的命令可以从这份命令列表获取,不同的命令都和不同的数据结构有关,简单来说有以下几种数据结构:
| 数据结构 | 应用场景 | 备注 |
|---|---|---|
| 字符串(string) | 简单值、复杂对象序列化 | 最长不超过512MB |
| 列表(list) | 队列、数据列表等 | |
| 散列(hash) | 字典 | |
| 集合(set) | 去重 | |
| 有序集合(zset) | 推荐榜 | 介于散列和集合之间 |
| 位图(bitmaps) | 实时分析,空间效率要求高的ID相关信息 | 并非真实的数据结构,其实是基于字符串类型的操作。512MB的限制使其可以最多表达位 |
| 超日志(hyperloglog) | 惟一性数据统计,节省内存 | 基于字符串编码的数据结构 |
redis除了支持上述数据结构相关的命令,还支持lua脚本、发布订阅模式等等服务器操作,也就是说redis不仅仅只是一个缓存服务器,它本身就可以实现很多复杂的功能而仅仅牺牲很小的性能损失。
正是基于前述的各种比较,决定选择redis作为系统缓存的核心组件。
设计方案
由于设计方案是redis 3.0的集群方案尚未有大规模成功实践的案例,因此在设计时仍然采用代理+redis sentinel的方案。为了便于将来redis原生集群功能成熟时可以更加平滑的切换,特地选择了redis3.0+版本作为核心服务器,整体方案如下:
| 数据库服务器 | 集群实现 | 共享/独占 | 命名空间 | 数据分片 | 持久化 | CPU核 | 内存 |
|---|---|---|---|---|---|---|---|
| redis 3.0.x | keepalived + Twemproxy + redis3.0 + sentinel + beholder | 共享 | YES | YES | YES | 4 | 8GB |
其中keepalived用于负载均衡,twemproxy用于前端数据分片代理, sentinel用于监控redis master节点状况,一旦出现失效进行slave切换。同时为了避免sentinel单点失效问题,sentinel也是配置成集群模式运行。beholder则用于主备切换后实时更新Twemproxy端的redis配置,使客户端可以透明的访问redis集群。
在系统设计时采用的各模块版本如下:
| 模块 | 版本 | 备注 |
|---|---|---|
| Keepalived | HA Proxy | |
| Twemproxy | 0.4.1 | |
| redis | 3.0.4+ | 不得低于最低3.0.41 |
| beholder | NA | https://github.com/Serekh/beholder.git |
[1]: 关于redis版本的选择,请参考redis3.0的release notes
--[ Redis 3.0.4 ] Release date: 8 Sep 2015 Upgrade urgency: HIGH for Redis and Sentinel. However note that in order to fix certain replication bugs, the replication internals were modified in a very heavy way. So while this release is conceptually saner, it may contain regressions. For this reason, before the release, QA activities were performed by me (antirez) and Redis Labs and no evident bug was found.
缓存系统的整体结构如下图所示:

集群的配置为
- Master节点默认端口6379,同一台机器上多个Redis主节点端口号按照:6379+offset,offset递增配置。
- 同一台机器上的集群,Slave节点默认端口号为对应Master节点端口号+1000+offset,offset递增。
- Twemproxy使用默认端口
- 测试环境在一台机器中配置Master-Slave两个Redis Instance
命名空间
由于系统整体采用Micro Service架构,共享式缓存会应用于多个服务以及多个服务内部节点之间的数据共享,因此,为了便于开发避免冲突,需要统一键空间命名规范。Redis支持多数据库(默认最多16个db,默认连接,不同的数据库可以通过SELECT 命令切换)存储,因此系统中不同的服务可以使用不同的db。但是由于Twemproxy代理不支持select命令,详情参见Redis Command Support,因此所有的键都是存储与中的
建议通用规则:service name:type:key_name:
| 服务名 | 命名空间 | 备注 |
|---|---|---|
| 保留服务(作为通用服务) | com:type:key_name | 全局通用 |
| User Service | user:type:key_name | |
| Product Service | prod:type:key_name | |
| Payment Service | pay:type:key_name | |
| Order Service | order:type:key_name | |
| Marketing Service | mkt:type:key_name | |
| Uitility Service | util:type:key_name |
其中,type采用缩写格式减少key长度:
| 类型名称 | redis类型 | 转义类型 | 备注 |
|---|---|---|---|
| 字符串 | string | str | |
| 列表 | list | list | |
| 集合 | set | set | |
| 有序集 | Zset | zset | |
| 散列表 | hash | hash | |
| 超日志 | HyperLogLog | hll | |
按照这个规则,为session增加一个缓存字段的Python示例如下:
from hashlib import md5
from redis import Redis
host = "192.168.1.147"
com_db, user_db = 0, 1
user = "zwjr"
conn = Redis(host=host, db=0)
session = md5(user).hexdigest()
conn.hset("com:hash:session", user, session)
r = conn.hget("com:hash:session", user)
通过redis-cli在命令行可以如下操作:
~/codes/zwjr » redis-cli -h 192.168.1.147
192.168.1.147:6379> select 0
OK
192.168.1.147:6379> HKEYS com:hash:session
1) "zwjr"
192.168.1.147:6379> HGET com:hash:session zwjr
"3e75dda0c18bb58237556e323d62ac1d"
192.168.1.147:6379>
Spring集成
我们的后台服务采用了Spring框架,因此实际开发过程中是利用Spring Data Redis来访问redis数据库的,同时Spring Data Redis支持多种redis客户端driver,使用比较广泛的有下列几个:
- Jedis
- JRedis
- Lettuce
- SRP
其中Jedis是使用最多的Java客户端,它提供了线程池可以最大限度的提高连接性能,因此最终选择了Jedis作为底层客户端驱动。
安全
由于redis的访问端口是可以对公网暴露的,而且存储在redis中的大量数据是以字符串形式裸存的,因此必须要对redis作一定的访问安全限制:
- 对外防止端口扫描 (http://static.nosec.org/download/redis_crackit_v1.1.pdf)
- 敏感数据必须加密存储